
Optical character recognition (OCR)
OCR in IWAC
OCR in practice: image and layout hurdles
Creating searchable text relies on optical character recognition (OCR), but the poor condition of many sources makes this a challenging task. Newspapers often exhibit faded ink on yellowing paper, damage resulting from tropical climates and bleed-through. Early digitisation using Frédérick Madore's mobile phone cameras in the early 2010s sometimes produced images that made OCR barely usable, necessitating near line-by-line verification. The shift towards digital evidence is therefore reshaping historical practices. OCR quality has become an invisible variable in the discovery process. Even a character error rate of 5–10% can render articles effectively unsearchable if it distorts proper names or key terms. As Torget (2022) demonstrates, OCR noise can influence and restrict the patterns apparent in large-scale analysis, rather than merely inconveniencing researchers.
Why newspapers break conventional OCR
A second, more challenging issue is structure. Even leading commercial OCR services, such as Google Document AI, struggle with layout analysis. As the figure below shows, a seemingly straightforward multi-column article was fragmented into disconnected blocks (blue boxes). The system failed to distinguish between the main text wrapping a central photograph and the adjacent, unrelated content. While characters were often recognised correctly, layout detection faltered. When systems cannot reconstruct how readers move from column to column, the result is a jumbled text stream that is poor input for computational analysis.
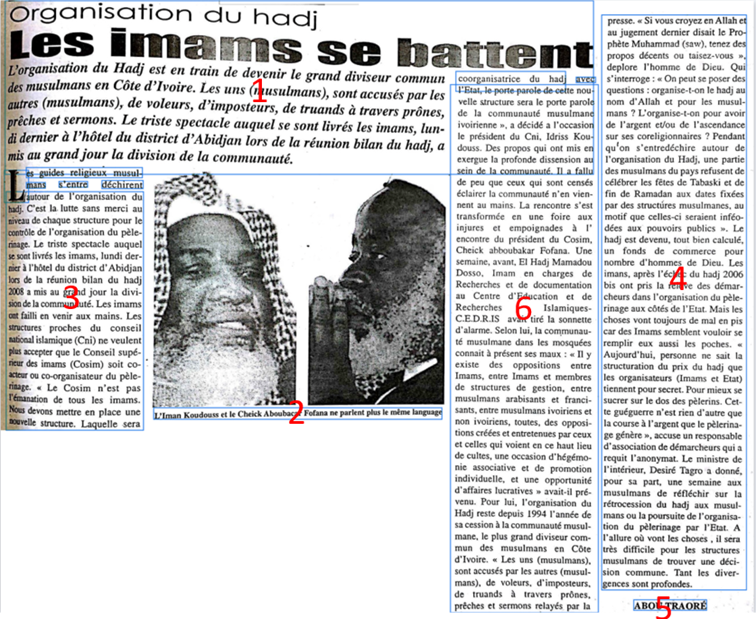
Traditional OCR tools are optimised for modern, well-structured documents such as letters and books. These tools rely on geometric assumptions, such as rectangular blocks and consistent alignments, which do not apply to newspapers due to their non-linear flow, multi-column structure and visual hierarchy. Although models can be trained to recognise layouts more effectively, the diversity of fonts, styles and formats across publications and decades makes this impractical for IWAC. In African archives, material degradation exacerbates the problem. Manual intervention was therefore essential, involving cropping relevant articles from full pages and tracing text flow through columns and continuations.
Human review where it matters
Initially, we maximised accuracy by manually reviewing all the text that had been extracted. This approach produced reliable results and minimised errors that distorted the content. However, as the corpus grew, this approach became unsustainable.
What LLMs add
Large language models (LLMs) represent a significant advancement. Unlike character-level OCR, they draw on broad linguistic knowledge to interpret context and infer the correct text from degraded signals, which is advantageous for historical newspapers. Recent studies report that multimodal LLMs now outperform specialised systems for recognising handwritten text, delivering transcription quality approaching that of humans in a fraction of the time and cost (Humphries et al., 2025).
Post-OCR correction with Google Gemini
In order to address the issue of inconsistent OCR quality in IWAC, Madore developed a Python-based pipeline that employs Google Gemini Flash 2.5 or Gemini Pro 2.5 for post-correction purposes. Its effectiveness stems from a combination of model capability and prompt design tailored to newspaper digitisation. The core instructions target:
- recurrent character confusions in degraded print (e.g., "rn"→"m", "cl"→"d");
- diacritic restoration (e.g., "etudes"→"études");
- word segmentation where tight kerning or damage creates false splits;
- preservation of proper nouns.
Uncertainty handling is explicit. For cases of medium confidence, the system selects the more conservative option (e.g., retaining "Ahmadou" over "Ahrnadou" when the context allows for it). For low-confidence spans, bracketed flags indicate uncertainty (e.g., "[date unclear: 19?3]"). To reduce hallucinations, long documents are divided into smaller sections to avoid the context window overflowing, which can otherwise trigger deletions or fabrications.
End-to-end multimodal extraction
A more radical shift comes from multimodal models such as Gemini Pro 2.5 in a separate Python pipeline. While these models are more expensive, they can analyse images and text together, performing layout analysis and extraction directly on page images. Rather than merely correcting OCR errors, they use visual cues (e.g. font changes indicating section breaks and spatial proximity indicating continuations) to achieve a level of document understanding similar to that of humans. Early experiments on challenging IWAC materials produced striking results: Gemini Pro 2.5 correctly identified article boundaries and reading order. For a corpus spanning six decades of changing design conventions, this adaptability is invaluable.
Risks: editorial drift, hidden errors, and reproducibility
Every AI intervention introduces an interpretive layer between the researcher and the source. When Gemini "corrects" text, it relies on training data that is largely influenced by Western linguistic norms. The tendency to modernise historical orthography by standardising regional spellings or toponyms risks erasing evidence of linguistic change. More troubling still is the opacity of these edits. Unlike human transcribers, who document their decisions, models operate as black boxes. A "clean" text can be indistinguishable from an invented one, and this uncertainty can affect subsequent analysis.
AI can also mask serious errors. While traditional OCR often signals failure through obvious garbling, AI can produce fluent prose that conceals inaccuracies. This veneer of accuracy can lead to overconfidence and discourage verification. Another concern is variability: the same document processed at different times may produce slightly different results as parameters change or resources fluctuate. Unlike the relatively predictable failure modes of OCR, the behaviour of LLMs remains opaque and non-deterministic, which challenges reproducibility—a cornerstone of scholarly method.
Safeguards and responsible use
These challenges call for careful deployment. The evolving workflow therefore:
- preserves original images alongside AI transcriptions;
- documents model versions, prompts, and processing parameters on GitHub;
- maintains auditable transformation logs.
In short, integrating LLMs into digital humanities (DH) workflows requires striking a balance between efficiency and authenticity, and between access and accuracy. IWAC demonstrates that these tools can make previously inaccessible archives, which were difficult to read due to poor OCR, available. While AI offers powerful capabilities, it can replace transparent failures with hidden fabrications.
Code and pipeline
OCR post-correction
https://github.com/fmadore/iwac-ai-pipelines/tree/main/AI_ocr_correction
OCR extraction
https://github.com/fmadore/iwac-ai-pipelines/tree/main/AI_ocr_extraction