IWAC chatbot
Why keywords fall short
Although keyword searches feel intuitive and fast, they miss meaning. Polysemy and synonymy scatter the results. This problem is exacerbated in historical sources due to language change, non-standard orthography and implicit concepts that do not align neatly with modern terminology. Poor data quality exacerbates this issue: OCR noise can obscure text, uneven metadata can skew retrieval, search ranking is often opaque, and our present-day phrasing can bias queries. As Huistra and Mellink (2016) observe, mass digitisation encourages scholars to approach sources "through specific words", which makes outcomes heavily dependent on repository search tools and risks leading to a distorted interpretation.
From strings to meanings: why RAG helps
We need a semantically-driven search that considers historically contingent meanings, not just exact strings. Retrieval-augmented generation (RAG) facilitates this change. RAG represents texts and queries as high-dimensional vectors (embeddings) that capture conceptual proximity rather than character matches. It can relate "hajj" to "pilgrimage" or connect "hijab" with "veiling practices" and "women's modesty", even when the terms do not overlap. Vector search also tolerates synonymy, historical variation and some OCR errors.
How the IWAC chatbot works
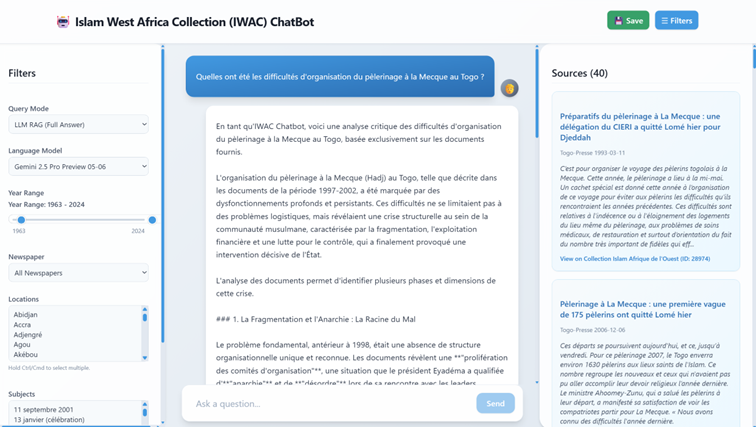
We are developing a conversational chatbot prototype for IWAC that indexes the newspaper collection by segmenting articles and converting them into embeddings. When a user asks a question such as "What were the difficulties of organising the pilgrimage to Mecca in Togo?", the system processes the query, retrieves the most relevant materials, and crucially returns the full article containing the relevant passage rather than isolated fragments. The assistant then presents the article(s) and the question to either an LLM (e.g. ChatGPT, Claude or Gemini) or an open-source model (e.g. Llama) with explicit instructions to answer based solely on the supplied text. This workflow preserves research integrity and maintains verifiable links to primary sources.
Getting prompt and context right
Two practices matter most: prompt engineering and context engineering. The prompt instructs the model to analyse, contextualise and infer only when the sources warrant it, using explicit conditional logic. To avoid unreliable LLM-formatted references, we separate the display of citations from text generation, and we tune the temperature to balance synthesis and the risk of hallucination.
Context must be sized carefully. Too little results in generic answers, while too much invites drift. Larger context windows increase capacity, but require more rigorous selection. The IWAC chatbot adjusts the retrieval parameters to ensure that the responses reflect the richness and gaps of the evidence.
Researcher-oriented interface
Users can filter by date, newspaper, location or subject using the facets feature. Each response includes citations and direct links to the relevant IWAC items for immediate verification.
What changes for users
Rather than relying on hit-or-miss keywords, users can now ask questions in natural language. The assistant provides contextualised responses and points to relevant documents. Semantic search reveals connections that keyword queries might miss. Unlike generic LLM chats, the assistant prioritises transparency and traceability, meaning every claim can be verified.
What it does not do
Although RAG improves access, it has its limitations. It may generate statements that are not present in the sources, have difficulty with temporal precision or produce different results for near-identical queries. It can also reflect the biases of the retrieved documents. No pipeline can eliminate hallucinations, and poor retrieval results in poor answers (Daugs et al., 2025). The assistant supports distant reading and complements close reading and critical judgement; it does not replace them.
Interim access via Google NotebookLM
While the assistant is being finalised, an IWAC workspace is available in Google NotebookLM, which Google describes as an "AI research tool and thinking partner". Around 11,500 IWAC newspaper articles have been loaded as sources. The workspace functions similarly to a RAG in that generation is grounded in the uploaded corpus, with citations linking back to specific passages. Users can select which newspapers to include, chat in over fifty languages and produce evidence-based outputs such as summaries, audio in the style of podcasts, video overviews, mind maps and structured reports. This interim pathway lowers barriers to exploration while preserving grounding, transparency, and traceability.