IWAC chatbot
Pourquoi les mots-clés sont insuffisants
Bien que les recherches par mots-clés paraissent intuitives et rapides, elles passent à côté du sens. La polysémie et la synonymie dispersent les résultats. Ce problème est accentué dans les sources historiques en raison de l'évolution de la langue, de l'orthographe non normalisée et de concepts implicites qui ne correspondent pas clairement à la terminologie moderne. La mauvaise qualité des données accentue davantage cette difficulté : le bruit de la ROC peut masquer le texte, des métadonnées hétérogènes peuvent fausser la recherche, le classement des résultats est souvent opaque et la formulation actuelle de nos requêtes peut biaiser les résultats. Comme le soulignent Huistra et Mellink (2016), la numérisation de masse incite les chercheurs à aborder les sources "par des mots spécifiques", ce qui rend les résultats fortement dépendants des outils de recherche des dépôts et risque de conduire à une interprétation déformée.
Des chaînes de caractères aux significations : pourquoi la RAG aide
Nous avons besoin d'une recherche guidée par la sémantique qui tienne compte des significations historiquement contingentes et pas seulement des chaînes exactes. La génération augmentée par récupération (RAG) permet de faciliter cette transition. La RAG représente les textes et les requêtes sous forme de vecteurs de grande dimension (ou embeddings) qui capturent la proximité conceptuelle plutôt que les correspondances de caractères. Elle peut ainsi relier "hajj" à "pèlerinage" ou associer "hijab" à la "pudeur féminine", même lorsque ces termes ne se recoupent pas. La recherche vectorielle tolère également la synonymie, les variations historiques et certaines erreurs de la ROC.
Fonctionnement du chatbot de la Collection
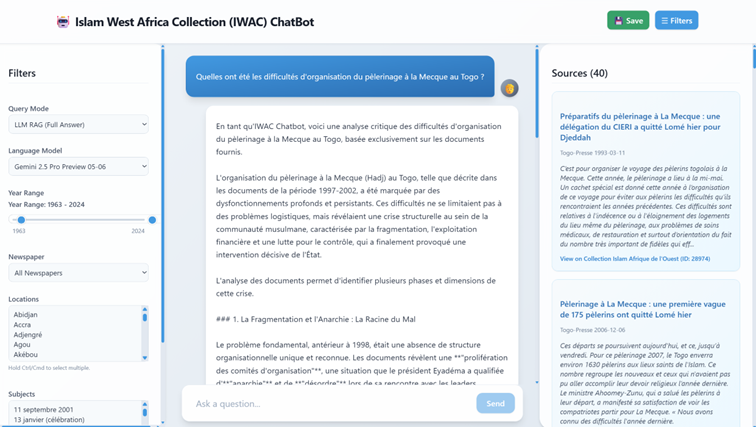
Nous développons un prototype de chatbot conversationnel pour la Collection qui indexe la collection de journaux en segmentant les articles et en les convertissant en vecteurs de représentation. Lorsqu'un utilisateur pose une question telle que "Quelles étaient les difficultés d'organisation du pèlerinage à La Mecque au Togo ?", le système traite la requête, récupère les documents les plus pertinents et, point crucial, puis renvoie l'article complet contenant le passage pertinent plutôt que des fragments isolés. L'assistant soumet ensuite le ou les articles ainsi que la question soit à un LLM (e.g. ChatGPT, Claude ou Gemini), soit à un modèle open source (e.g. Llama), avec des instructions explicites pour répondre uniquement à partir du texte fourni. Ce flux de travail préserve l'intégrité de la recherche et permet de maintenir des liens vérifiables vers les sources primaires.
Soigner le prompt et le contexte
Deux pratiques sont essentielles : l'ingénierie du prompt et l'ingénierie du contexte. Le prompt incite le modèle à analyser, à contextualiser et à inférer uniquement lorsque les sources le justifient, en recourant à une logique conditionnelle explicite. Pour éviter les références au format LLM peu fiables, nous séparons l’affichage des citations de la génération de texte et ajustons la température afin d'équilibrer la synthèse et le risque d'hallucination.
Le contexte doit donc être soigneusement dimensionné. Un contexte trop restreint conduit à des réponses génériques, tandis qu'un contexte trop large favorise la dérive. Des fenêtres de contexte plus larges augmentent la capacité, mais exigent une sélection plus rigoureuse. Le chatbot ajuste les paramètres de récupération afin de garantir que les réponses reflètent la richesse et les lacunes des preuves.
Interface orientée chercheurs
Les utilisateurs peuvent filtrer les résultats par date, journal, lieu ou sujet grâce à la fonctionnalité de facettes. Chaque réponse inclut des citations et des liens directs vers les éléments pertinents de la Collection, permettant ainsi une vérification immédiate.
Ce qui change pour les utilisateurs
Plutôt que de s'appuyer sur des mots-clés hasardeux, les utilisateurs peuvent poser des questions en langage naturel. L'assistant fournit des réponses contextualisées et renvoie vers des documents pertinents. La recherche sémantique permet de mettre au jour des liens que des requêtes par mots-clés pourraient manquer. À la différence des chatbots LLM génériques, l'assistant accorde la priorité à la transparence et à la traçabilité, ce qui signifie que chaque affirmation peut être vérifiée.
Ce qu'il ne fait pas
Bien que le RAG améliore l'accès, il a ses limites. Il peut notamment générer des énoncés absents des sources, rencontrer des difficultés de précision temporelle ou produire des résultats différents pour des requêtes quasi identiques. Il peut également refléter les biais des documents récupérés. Aucun pipeline ne peut éliminer les hallucinations et une récupération documentaire défaillante produit de mauvaises réponses (Daugs et al., 2025). L'assistant soutient la lecture à distance et complète la lecture rapprochée ainsi que le jugement critique ; il ne les remplace pas.
Accès provisoire via Google NotebookLM
Pendant la finalisation de l'assistant, un espace de travail IWAC est disponible dans Google NotebookLM, un "outil de recherche en IA et partenaire de réflexion" selon Google. Environ 11 500 articles de presse d'IWAC ont été chargés comme sources. Cet espace fonctionne de manière similaire à un RAG : la génération est ancrée dans le corpus téléversé, avec des citations renvoyant à des passages précis. Les utilisateurs peuvent sélectionner les journaux à inclure, dialoguer dans plus de cinquante langues et produire des résultats fondés sur des sources, tels que des résumés, des podcasts, des synthèses vidéo, des cartes heuristiques et des rapports structurés. Cette solution intermédiaire permet de réduire les barrières à l'exploration tout en préservant l'ancrage, la transparence et la traçabilité.